“Learn to prompt.”
Palmer Luckey
Predicting the next technological breakthrough is like predicting the next fashion trend. Even if it’s a good product, you just never know if it’ll catch on.
Before the launch of ChatGPT in 2022, some in tech predicted that virtual reality would become the next major computing platform, while others claimed blockchain and cryptocurrency would underpin “Web 3.0.” While both of those technologies may have some merit, they also attracted plenty of skeptics. Generative AI, by contrast, enjoys broad agreement that it will be transformative.
In 2019, three years before ChatGPT’s launch, research from MIT Sloan found that AI-driven productivity gains had been slow to materialize – but went on to explain that this was generally in line with other transformative “general-purpose” technologies, such as electricity. Once such a technology is introduced, it takes decades of skill-building and follow-up investments before productivity gains really take off, a pattern economists call the “J-curve,” named for its long flat bottom followed by a sharp upward climb. At the time, the researcher wrote, “We think AI may be in the early part of the J-curve now.” Today, with generative AI in the hands of hundreds of millions of people, it’s reasonable to argue we’re moving further up that curve.
What is AI?
At its simplest, AI refers to the ability of computers to mimic human cognitive functions rather than just follow static commands. This includes cognitive intelligence (detecting patterns) and generative intelligence (creating text, code, and images).
By that broad definition, AI has been around for many years. With regard to pattern detection, machine learning (a subfield of AI) is a practice in which computers adjust their behavior from additional data without the need for direct changes to its programming, allowing them to handle more complex tasks.
For example, when you move an email to your Spam folder, you’re giving your email service provider an additional example of a spam email that it can use to better classify future emails. This example of using labeled data to train a model to make prediction is called supervised machine learning.
By contrast, with unsupervised machine learning, a model is required to detect patterns in unlabeled data. Such unsupervised techniques can be used to detect anomalies, such as when your bank’s fraud prevention department calls you to tell you that they think you made an unusual purchase.
Additionally, deep learning (DL) is a branch of machine learning that involves the use of deep neural networks – a computational model inspired by the structure and functioning of the human brain – to process information. Deep neural networks are designed as several layers of interconnected nodes that receive data, perform computations, and generate output. The “deep” part of the name comes from those networks containing multiple hidden layers between the input and output layers, which allows the network to learn increasingly intricate and abstract representations of the input data, leading to the extraction of higher-level capabilities like image recognition, natural language processing, and speech recognition. Since DL is subfield of ML, both can encompass “supervised” and “unsupervised” learning techniques.
Deep neural networks can have many different architectures, including convolutional neural networks (CNNs) and recurrent neural networks (RNNs), such as Long Short-Term Memory (LSTM) networks. Each architecture is designed to handle specific types of data or solve particular problems. For example, CNNs are behind many popular image recognition features, like facial unlock in smart phones, and photo tagging in social media. While early virtual assistants utilized LSTMs for natural language processing.
While spam and fraud detection do involve artificial intelligence and machine learning techniques, no one was ever quick to label it AI because these tasks, while useful, don’t intuitively feel like human interaction. That is where large language models come in.
Why AI got so good all of a sudden
The reason generative AI has gotten so good that it now feels more like human interaction, is due to a breakthrough in neural network architecture. In 2017, Google published a paper titled “Attention is All You Need” which introduced the transformer deep learning model. This model uses the self-attention mechanism to allow for the relationships between text to be captured in a sequence, rather than one word at a time (as RNNs do). It does this by maintaining a stack of encoder and decoder layers. The encoder layers convert the input sequence into a sequence of vectors, and the decoder layers generate the output sequence. Each layer in the Transformer uses the attention mechanism to focus on different parts of the input or output sequence.
This leap in parallelization means a model can now get trained on enormous amounts of text data super-fast, as long as you have the hardware to do so. This sparked a boom in demand for GPUs (Graphics Processing Units). Originally designed to render video game pixels in parallel, NVIDIA’s chips were perfectly adapted to process the parallel math required for AI training.
Pre and Post Training
Once the hardware is secured, significant investment must also be made in building the training data. This data, drawn from sources like books, websites, articles, papers, and forums, is preprocessed to remove low-quality content, duplicate information, and offensive content. This text is then tokenized, which means converted from chunks of text (generally ~4 characters or 0.75 words) into numerical form, known as token IDs (click here to test how a string of text may be tokenized). This tokenization process helps the model understand the statistical relationships between words.
Today’s state-of-the-art models are trained on multiple trillions of tokens. During this training, the model continuously updates its parameters, including its “weights” and “biases.” Weights are numerical values representing the strength of connections between neurons. A higher weight indicates a stronger influence between two neurons. These weights are adjusted during training to minimize the difference between the model’s predictions and the actual data, represented by a loss function. The goal is to minimize the loss but not drive it to zero (if the model learns the training data too well, such as unnecessarily specific detail, rather than general patterns, it won’t perform well on new data, this is called “overfitting”).
Biases are also updated during training. These numerical values shift the activation function of neurons, enabling them to fire (pass their output to the next layer) even with zero input and contributing to the model’s ability to learn complex functions.
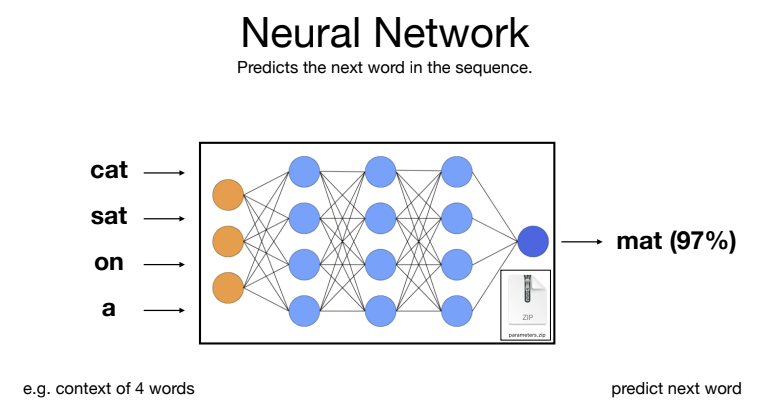
To use an analogy, if you think of each neuron like a courtroom, the weights are the level of importance placed on each piece of evidence (inputs), and the bias would be the judge’s initial predisposition. In a language model, the inputs might be the preceding words or parts of words (tokens) in a sentence. Some inputs (or evidence) are more important than others for predicting the next word, but the overall strength of the evidence, its importance (weights), and the judge’s bias are all combined to reach a verdict, which is a numerical value representing the likelihood of a specific next word or token. This numerical verdict is the neuron’s output. If the neuron is sufficiently ‘activated’ (i.e., if the verdict reaches a certain threshold), that output can serve as evidence in another courtroom (another neuron), which may have its own weight placed on that verdict. After being trained on large datasets to optimize these weights, models can make shockingly accurate predictions about the next word or token in a sequence of text.
Imagine the current words are “The cat sat on the”. A courtroom (neuron) might receive evidence (inputs) like “The,” “cat,” “sat,” “on,” and “the.” The weights would determine how much importance is given to each of these preceding words. The bias might predispose the courtroom towards common words like “mat” or “floor.” The final verdict would be a set of numerical values, each representing the likelihood of a different next word. For example:
- “mat”: 0.97 (97%)
- “floor”: 0.02 (2%)
- “table”: 0.005 (0.5%)
- “rug”: 0.005 (0.5%)
Once a model is proficient at predicting the next token in a string of text (pre-training), it still needs additional training to convert this ability into providing general purpose human assistance. This is where fine-tuning comes in. At OpenAI, fine-tuning includes “instruction tuning,” in which human-written input templates are paired with desired output statements, and that dataset is used to help models better understand human instructions.
Next, you want to ensure responses are as high quality as possible, and align with human values. Therefore, a reward-based fine-tuning method called Reinforcement Learning with Human Feedback (RLHF) was developed. The basic idea behind RLHF is that humans rank outputs generated from the same prompt, and the model learns these preferences so that they can be applied to other generations at greater scale (reward model). This process is perhaps the biggest differentiator, as it trains the model to know what a good response looks like. Full paper: OpenAI paper “Training language models to follow instructions with human feedback.”
The basic principles behind pre and post training is that Pre training is like teaching a kid through imitation, reinforcement learning is like teaching them through trail and error. In general, reinforcement learning is the more powerful method (just as it is for kids).
Choosing (and then Using) an LLM
Once a model is trained and optimized for human assistance, it’s still important for the human to know a little bit about how to use it. Even without trying, LLM responses may look impressive, but to get exactly what you need, extra descriptiveness is crucial. This is because LLMs aren’t “reading” or “answering” your question in any literal sense, but are actually just generating a response to a prompt based on the patterns its learned from its training dataset. OpenAI has some best practices for prompt engineering.
With that said, if you’re simply looking to gain some quick knowledge on a subject, then short clauses like “Tell me about” or “Explain” work just fine. If it’s more specific or niche information I need, or if I’m seeking as high quality of an answer as possible, then more descriptiveness is needed. OpenAI has good examples below:
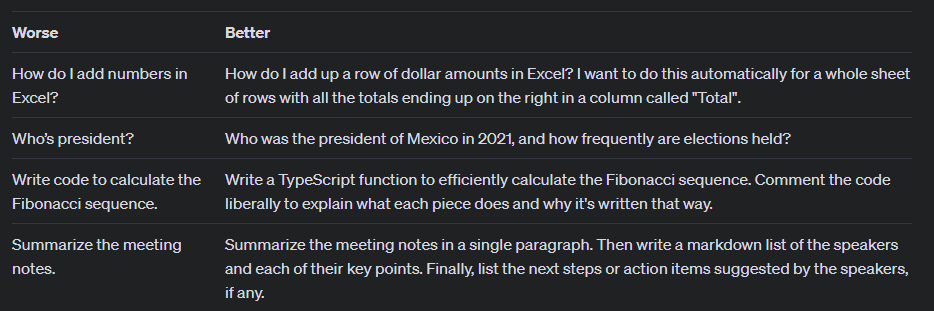
Source: here
Another powerful tactic is “persona prompting” in which you prompt the LLM to “Act as a…” or “You are a…”.
Basic prompt:
Please edit this sentence
Persona prompt:
You are an expert proofreader and editor. Can you please review this sentence and suggest any changes for grammar, readability, and clarity? Explain the changes you make.
The first prompt gave me an edited sentence, and nothing more. The second one gave me an edited sentence, a description of all the changes it made, and an explanation for why it led to improvement in readability while maintaining the original meaning. Even though it was fully able to do so this after my first prompt, I didn’t ask it to, so detailed prompting is important to get the most out of LLMs.
Once you find a detailed prompt that works well for you, you may not want to have to retype it every time you want to use it. In those cases, it may make sense to create a prompt bot. Such as on Poe or in OpenAI’s GPT Store. With a prompt bot, you write all the detailed instructions into a “system prompt” for it to be saved as a standalone bot you can use and reuse as often as you want. Again, I prefer Poe for this service because then I’m not limited to a single model provider. Poe is also a legit product created by Quora and its founder and CEO Adam D’Angelo, an early Facebook executive and current OpenAI board member who worked on his first AI product with Mark Zuckerberg in 2002. So they have a lot of credibility within the space.
For my prompt bot, because I found myself asking for editing and proofreading assistance a lot and I created a prompt bot on Poe called Writing-Instruct. It utilizes GPT’s high writing benchmarks along with a long, detailed prompt to give me the exact writing assistance I need, along with instruction to help me remember important tips and not let my own writing skills atrophy.
Reasoning models
There is one exception to the rule of writing your prompts with great detail and descriptiveness, and that is when you’re using a reasoning model instead of a standard large language model. Reasoning models incorporate step-by-step (also known as “Chain of Thought”) reasoning to break down complex problems, verify their own logic, and self-correct errors before generating the final answer. This makes reasoning models better for math, science, and coding tasks, but less effective for creative tasks. It also means they work better with simple, straight-to-the-point prompts instead of overly detailed prompts.
One analogy I heard was to think of typical large language models like children, in that they don’t think before they speak, whereas reasoning models do think. This higher intelligence comes with the trade-off that they are slower and more expensive due to the extra “hidden” tokens they generate while thinking.
Which LLM to use
When deciding which LLM to use, you should first aim to use the latest, most intelligent model. “Most intelligent” many often means the largest model by parameter size. As the more parameters means more relationships formed between tokens of what would have to be an extraordinary large training dataset.
To find the best performing models, check out Chatbot Arena, a crowd-sourced benchmarking platform for LLMs, hosted by researchers at UC Berkeley SkyLab and LMArena. Also, Scale AI publishes a leaderboard of the latest frontier models and how they perform in many categories.
Should cost or access be an issue, most other LLMs will work just fine for general purpose assistance. Microsoft, Google, and Meta have already integrated their models with many of their apps. So, LLMs are increasingly becoming ubiquitous.
For more complex tasks or problems, then I suggest going to directly to OpenAI, Gemini, or Anthropic. Or, experimenting with all of them on a site like Poe. Whoever has the “best” AI for certain tasks seems to change every month. So I enjoy experimenting with all of them.
Climbing the J-Curve
If AI is going to disrupt the future, as many predict, it will reward people who understand the basics and can apply them to domain-specific work today. We’re already seeing early disruption: in film, AI-generated voices and actors are reshaping production; in law, tools automate routine tasks; and in health care, systems transcribe clinician–patient conversations into structured notes (and, in some settings, support coding workflows).
But the real “boom” on the upward part of the J-curve will take years of organizational redesign: new processes, new roles, new safeguards, and new ways to measure quality. That’s hard to plan because the models keep improving. The upside is that anyone who learns to use AI well now has a chance to be ahead of the curve.